
Memory Efficient Hierarchical Neural Architecture Search For Image Denoising
Memory-Efficient Hierarchical Neural Architecture Search for Image Denoising (HiNAS)
Memory-Efficient Hierarchical Neural Architecture Search for Image Denoising
Neural Architecture Search (NAS) and Differential Architecture Search (DARTS) explained.
Image Denoising
Images are always contaminated by noise during an image sensing process. With the presence of noise, the visual quality of the collected images are degraded. Therefore, image denoising plays an important role in various computer vision tasks.
Image denoising underlying goal is to restore a clean image from a noisy image.
Neural Architecture Search
Neural Architecture Search (NAS) is a research field that first emerged from the efforts to automate the architecture design process with an aim to design the most optimal neural network architecture for a given task.
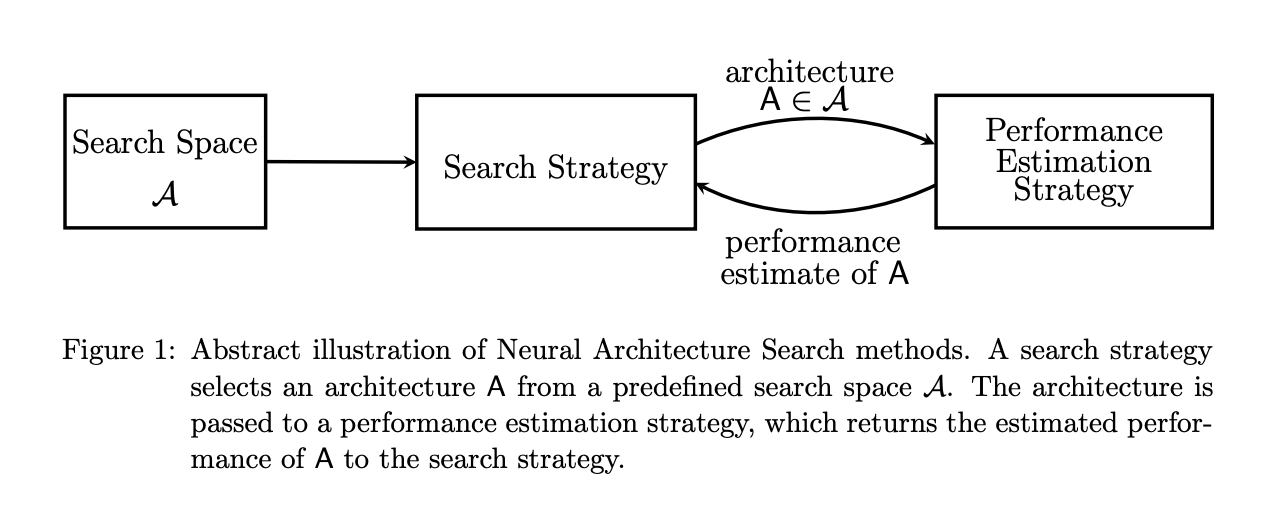
Summary of the NAS algorithm:
- a candidate architecture A is selected from a pre-defined search space
- the proposed architecture is passed to performance estimation strategy and the estimated performance is returned
- Based on the search strategy, the next candidate is proposed.
Search space: The NAS search space defines a set of operations (e.g. convolution, fully-connected, pooling) and how operations form network architectures. The search space determines the neural architecture to be assessed.
Search Strategy: The search strategy is used to choose a candidate from a population of network architecture and to avoid bad architectures. Child model performance metrics act as a reward to generate high-performance architectures. There are many search strategies such as Reinforcement Learning, Bayesian Optimization, Evolutionary Algorithms, Gradient-Based Optimization, or even Random Search.
Performance estimation strategy: feedback for the search algorithm is obtained from the predicted the performance of a large number of proposed models.
NAS for CNN
paper referenced: An Introduction to Neural Architecture Search for Convolutional Networks
There are two general approaches to Search Spaces in NAS for convolutional layers.
Global Search Space
First we have the Global Search Space (with the search known as macro-architecture search) which allows the optimization algorithm to generate arbitrary networks. For each network the algorithm chooses each layer’s type, hyperparameters and connections with other layers.
Micro or Cell based Search Space
HiNAS uses the cell based search space method - and more specifically Hierarchical Search Spaces which we will read about later. Micro or Cell based Search Space methods limits the optimization algorithm from creating arbitrary networks.
Motivated by the many effective handcrafted architectures designed with repetitions of fixed patterns, A cell-based search space consists of repeated blocks of layers called Cells.
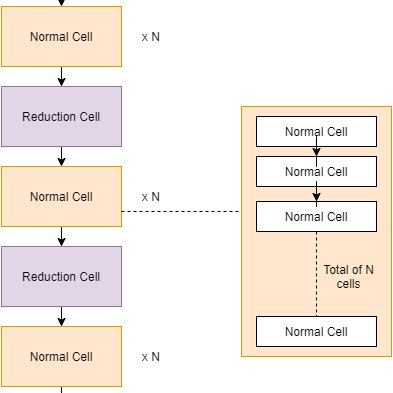
Hierarchical Structure
In many NAS methods, both macro and micro architectures are searched in a hierarchical manner.
Hierarchical structures start with small sets of primitives, including individual operations (e.g. convolution operation, pooling, identity). Then small sub-graphs also known as motifs consist of primitive operations that are used to form higher-level computation graphs.
A computation motif at starting at the lowest to the highest level ℓ=1,…,L can be represented by (G(ℓ),(ℓ)), where:
(ℓ) is a set of operations, (ℓ)={o(ℓ)1,o(ℓ)2,…}
An adjacency matrix G(ℓ) specifies the neural network graph of operations, where the entry Gij=k indicates that operation o(ℓ)k is placed between node i and j.
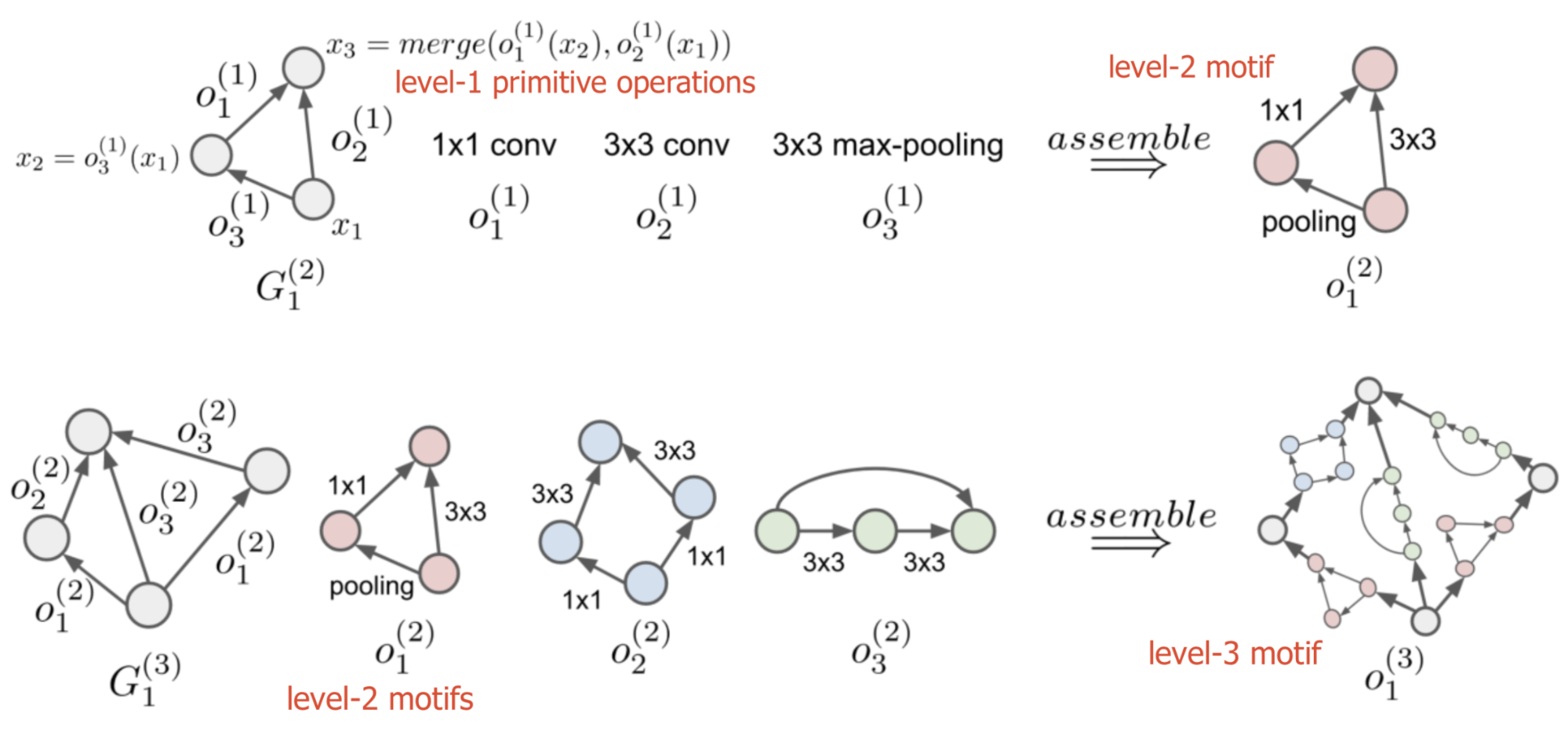
(Illustration of the assembly process) An example of a three-level hierarchical architecture representation. The bottom row shows how level-1 primitive operations o1(1), o2(1), o3(1) are assembled into a level-2 motif o1(2). The top row shows how level-2 motifs o1(2), o2(2), o3(2) are then assembled into a level-3 motif o1(3). Hierarchical Representations for Efficient Architecture Search
To build a network according to the hierarchical structure, we start from the lowest level ℓ=1 and recursively define the m-th motif operation at level ℓ as
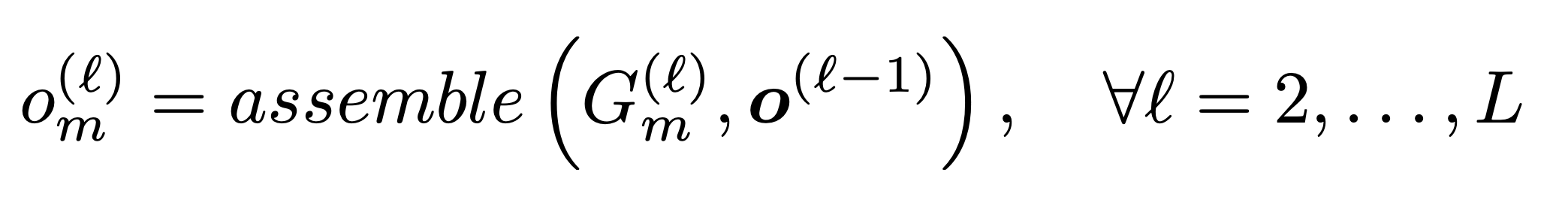
A hierarchical architecture representation is defined by,
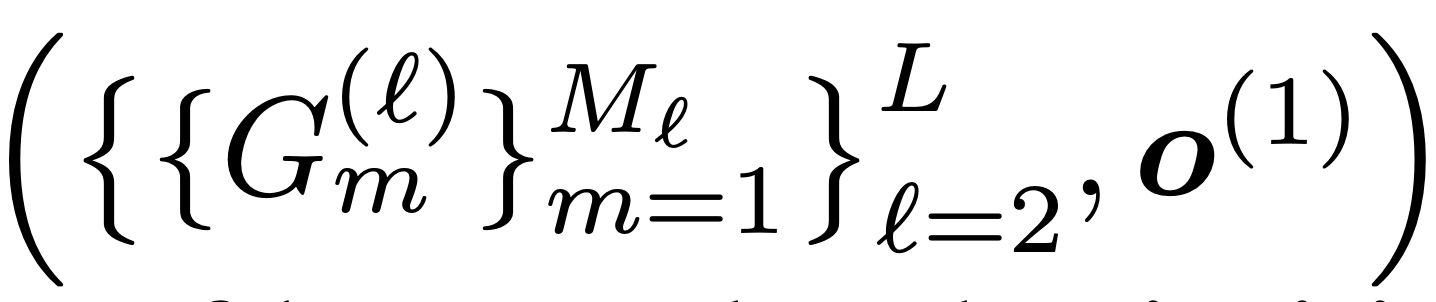
as it is determined by network structures of motifs at all levels and the set of bottom-level primitives.
Differential Architecture Search (DARTS).
DARTS: Differentiable Architecture Search
Differentiable Architecture Search (DARTS) is an efficient gradient-based search method which has been published at ICLR 2019.
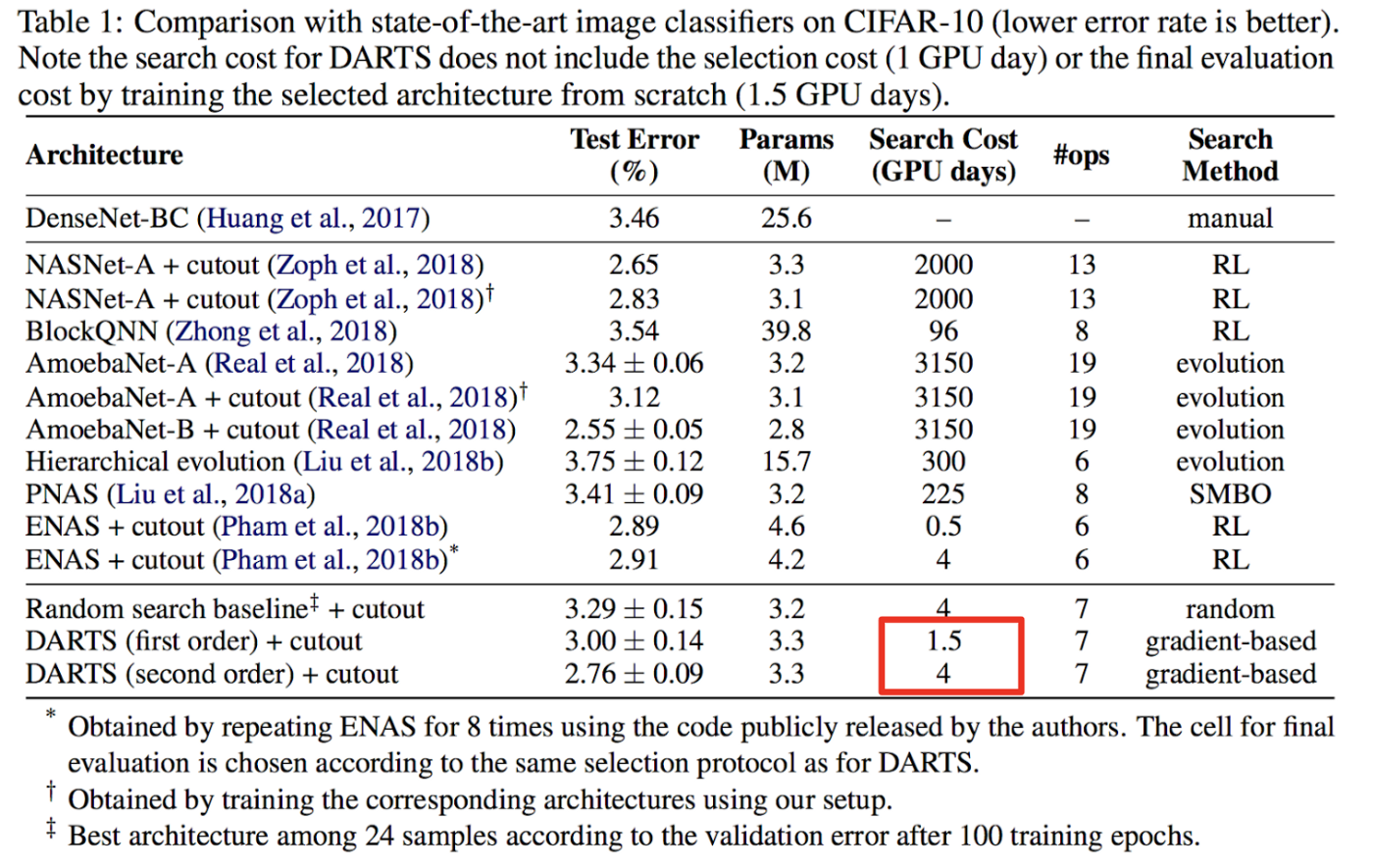
Improvements.
DARTS is shown to find architectures in image classification in only a matter of a few GPU days while archiving state of the art performance.
There are 3 keys ideas that makes DARTS efficient:
(1) only search for small “cells”,
(2) weight sharing,
(3) continuous relaxation.
NAS search spaces are discrete for example one architecture differs from the other by a layer, parameter, filter size etc. In DART continuous relaxation is introduced to enable direct gradient-descent optimization to the discrete search.
The cell we search can be though as a directed acyclic graph where each node x is a latent representation (e.g. a feature map in convolutional networks) and each directed edge (i, j) is associated with some operation o(i,j) (convolution, max-pooling, etc) that transforms x(i) and stored a latent representation at node x(j)
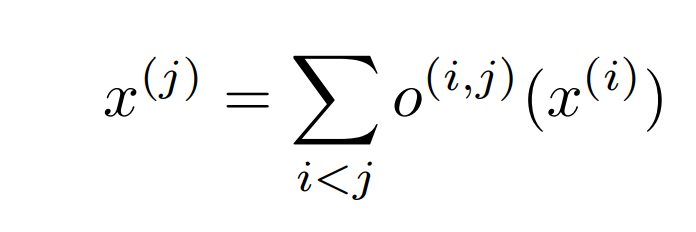
the output of each node can be calculated by the equation on the left. The nodes are enumerated in such a way, that there is an edge(i,j) from node x(i) to x(j), then i<j.
In order to transform the problem of architecture search to a continuous one, let us consider a set O of operations, such as convolutions, dilated convolutions, max pooling, and zero (i.e., no connection). We can then parametrize o(i,j) as
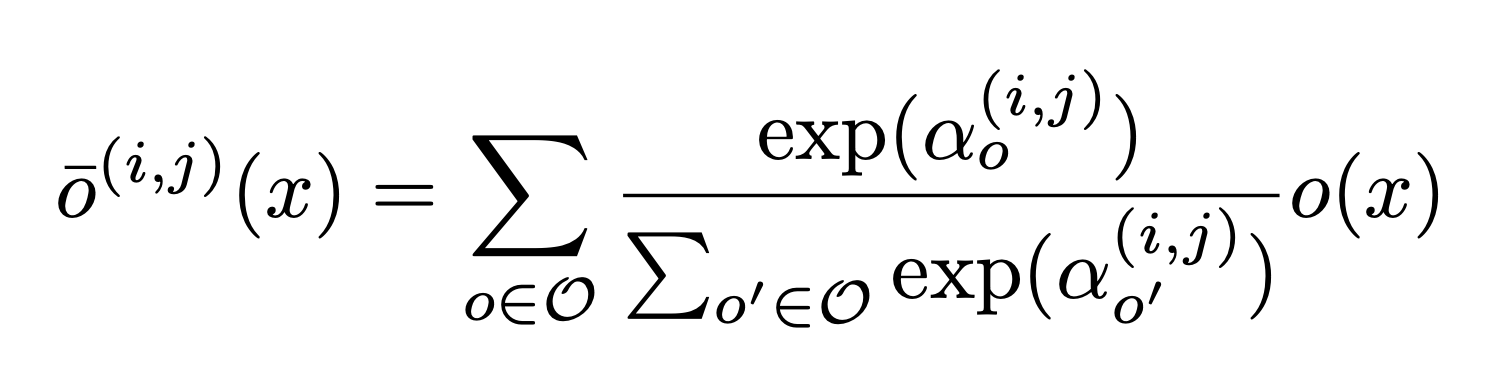
This is done with a softmax function.
The training loss L_train and validation loss L_val are determined by the architecture parameters α and weights ‘w’ in the network. The aim of the architecture search is to find α∗ of the validation loss L_val(w ∗ , α∗ ) to be minimized, where the weights ‘w*’ associated with the architecture is obtained by minimizing the training loss.
w∗ = argmin L_train(w, α∗ ).
α * = argmin L_val(w ∗ (α), α)
s.t. w ∗ (α) = argmin L_train(w, α)
The approximate gradient can be found since α is now continuous. ξ is assumed to be the step of an inner optimization learning rate.
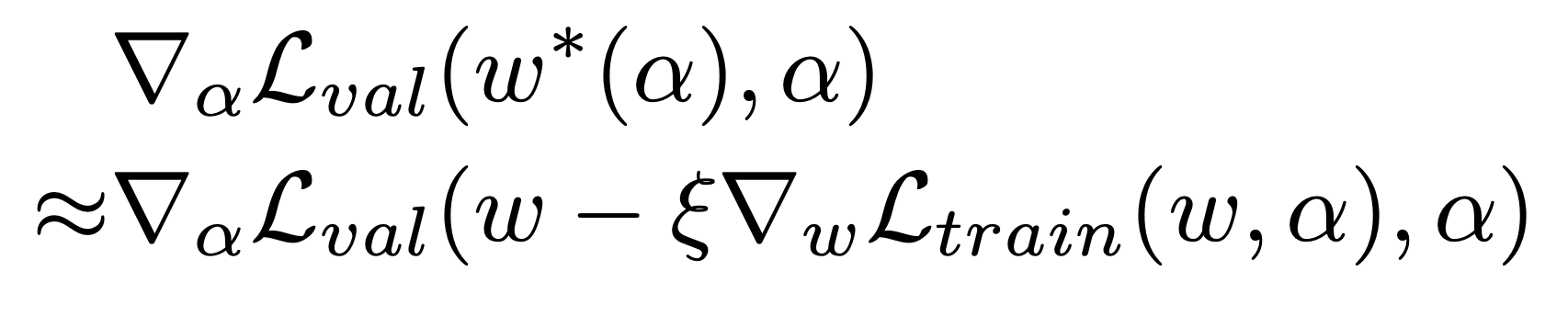
In continuous relaxation, instead of having a single operation between two nodes. a convex combination of each possible operation is used. To model this in the graph, multiple edges between two nodes are kept, each corresponding to a particular operation. And each edge also has a weight α.
After training some α’s of some edges become much larger than the others. To derive the discrete architecture for this continuous model, in between two nodes the only edge with maximum weight is kept.
Auto-Deeplab
Auto-Deeplab : Hierarchical Neural Architecture Search for Semantic Image Segmentation
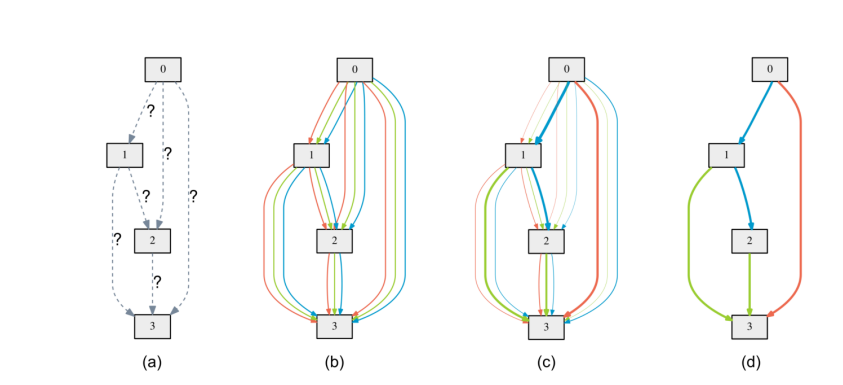
DARTS only searches for the best cells (micro) in a given architecture and does not search for the best architecture on a network level. Auto-Deeplab searches the network level structure in addition to the cell level structure, forming a hierarchical search space.
This is done by augmenting the cell level search space with a trellis-like network level search space. The architecture is then decoded using the Viterbi algorithm to keep the path with the strongest connections (maximum probability) in the trellis.
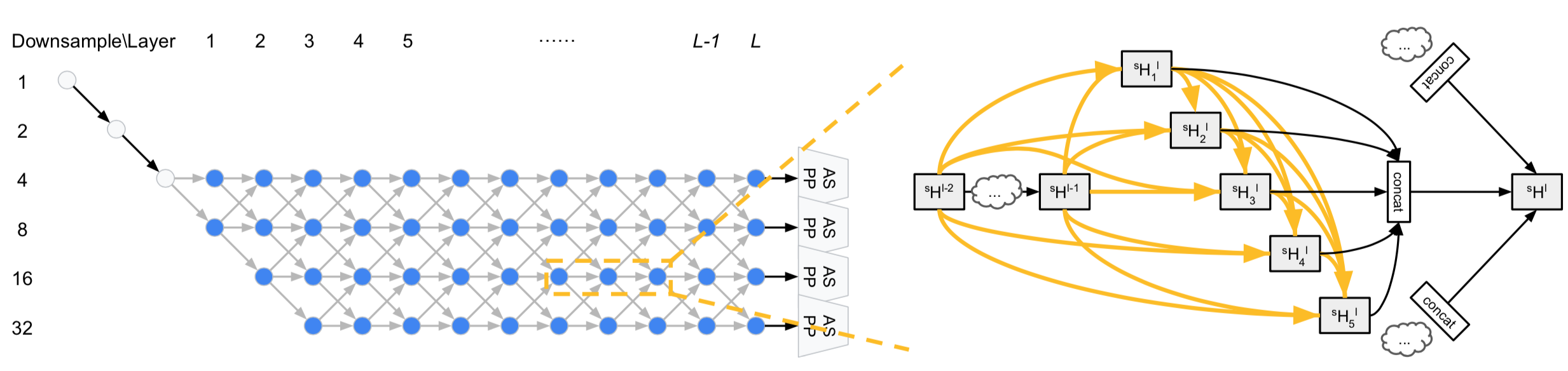
Auto-Deeplab is proposed for an image segmentation task. Downsampling strategy is reasonable for an image classification class, however there are network variations for dense prediction tasks as spatial resolution needs to be kept high.
Network Search implementation
The two principles are noticed to be consistent:
- The spatial resolution of the next layer is either twice as large, or twice as small, or remains the same.
- The smallest spatial resolution is downsampled by 32
First two layers of the architecture are downsampling layers and spatial resolution is reduced by a factor of 2. With the goal to find a good path in L-layer trellis, the further layers (total L-layers) are of unknown spatial resolutions, either being upsampled or downsampled by a given range.
Memory-Efficient Hierarchical Neural Architecture Search for Image Denoising
Hierarchical NAS (HiNAS) is a NAS to design effective neural network architectures for image denoising tasks.
HiNAS is both memory and computation efficient and is said to take 4.5 hours for searching on a single GPU.
Motivated by the search efficiency, HiNAS is implemented with gradient based search strategies employing the continuous relaxation strategy proposed in DARTS.
The search space of HiNAS resembles Auto-Deeplab, by introducing multiple paths of different widths. Flexible hierarchical search space is employed and the task of deciding the width of each cell to the NAS algorithm itself is left to make the search space more general.
However there are three major differences with Auto-Deeplab which are:
1) HiNAS relies on operations with adaptive receptive fields such as dilated convolutions and deformation convolutions to preserve pixel-level information. Instead of using downsample layers.
2) The cell is shared across different paths leading to improvements in memory efficiency.
3) Employed early stopping strategy to avoid the NAS collapse problem.
Both DARTS and Auto-Deeplab are proposed for high-level image understanding tasks. DARTS is proposed for image classification and Auto-Deeplab finds architectures for semantic segmentation. Whereas HiNAS is proposed for low-level image restoration tasks.
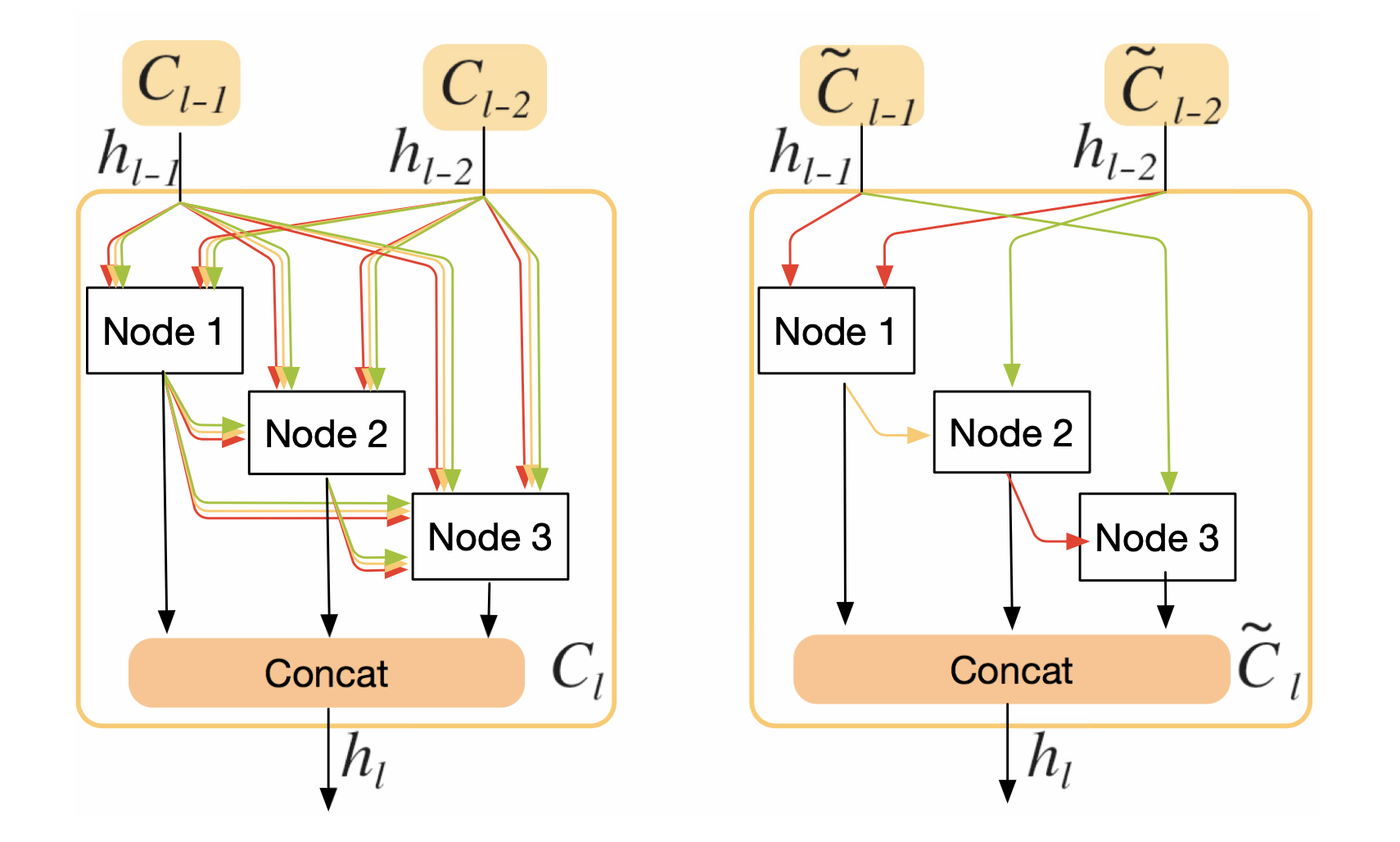
Cell Sharing

In Auto-Deeplab, the outputs from the three different levels are processed first by separate cells of different weights then summed into the output. Equation used to select features strides for image segmentation.
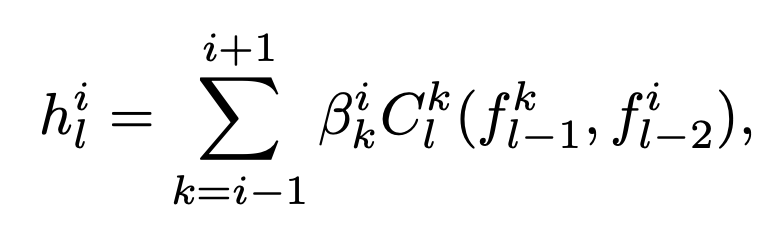
By sharing the cell, HiNAS saves memory consumption by a factor of 3 in the supernet (example given).
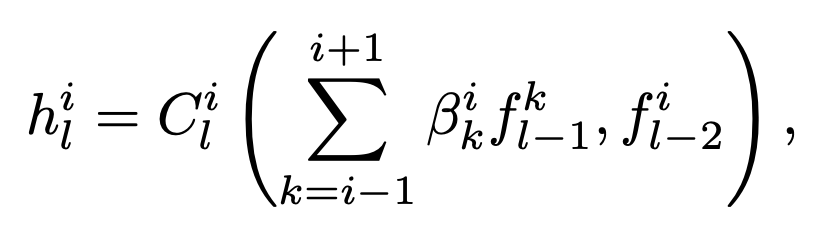
HiNAS implementation
HiNAS advantages:
- gradient based search strategy. HiNAS only needs to train one supernet in the search stage unlike Evolutionary Algorithms based NAS method.
- Cells shared across different feature levels, thus saving memory consumption.
- early-stopping search strategy.
Metrics used to evaluate model for image denoising are PSNR and SSIM.